In this post we will learn about Keras, one of the frameworks that make it easier to start developing deep learning models, and is versatile enough to build industry-ready models in no time.
In order to learn Keras better we will set-up an exercise we are going to solve in this post.
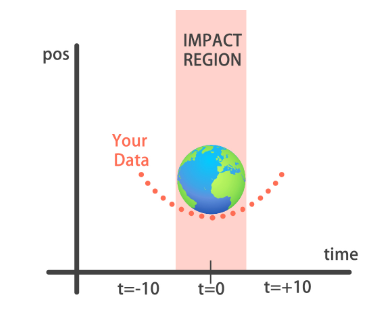
Problem Statement: Imagine a meteor is approaching the earth and a group of scientists is trying to estimate the orbit by using historical data gathered about previous orbits of similar meteors.
Scientists have used this data alongside their knowledge to estimate an 80-minute orbit, that is, an orbit from -40 minutes to +40 minutes. t=0 corresponds to the time of crossing the impact region. It looks like the meteor will be close!
We have data for the path a previous meteor took during a period of 20 minutes, 10 minutes before and 10 minutes after crossing the impact region. We will train a model on this data and then extrapolate our predictions to an 80-minute orbit to see how it compares to the scientists prediction.
Let us begin!
- That one thing which is here to stay is Deep Learning!
- That one thing which is the go-to technique to solve complex problems is Deep Learning!
- That one thing which can improve their performance over time, without the need for explicit programming is Deep Learning!
What is Deep Learning?
The subfield of machine learning that is inspired by the structure and function of the brain, specifically the neural networks that make up the brain. It involves the use of artificial neural networks, which are algorithms designed to recognize patterns and make decisions based on input data. It works with unstructured data.
What is Unstructured data?
Unstructured data is a type of data that does not conform to a predetermined data model or schema. It is typically not organized in a way that allows for easy interpretation or analysis, and often requires additional processing in order to extract useful information from it. Examples of unstructured data include text documents, emails, social media posts, audio and video files, and images.
In this post we will learn to run a regression and save the earth by predicting asteroid trajectories, but before moving to the practical session there is some important theoretical question we shall address.
What is Keras?
Keras is an open-source software library that provides a Python interface for ANNs (artificial neural networks). It was developed with the goal of making it easier for researchers and developers to build, train, and deploy machine learning models.
Keras is a high-level library for building and training neural networks. It is different from Theano.
Theano is also an open-source software library which is commonly used for working with large-scale numerical computations, such as those required when training deep learning models. However, building a neural network in Theano can take many lines of code in contrast to Keras.
Keras can be used with a variety of backends, including Theano, TensorFlow, and Microsoft Cognitive Toolkit (CNTK).
Why learn Keras?
1) Ease of use: Keras is designed to be simple and easy to use, with a high-level API that allows users to quickly build and train neural networks.
2) Modularity: Keras allow users to easily customize and build on top of existing models.
3) Allows users to choose the backend that best fits their needs: Keras can be used with a variety of different backends, including TensorFlow, Theano, and Microsoft Cognitive Toolkit (CNTK).
4) Wide adoption: There is a wealth of documentation, tutorials, and resources available for learning and using Keras.
5) Deployment: Keras models can be deployed across a wide range of platforms like Android, iOS, web-apps, etc.
Keras is fine, but why do we use neural networks in the first place?
Neural networks are particularly well-suited for working with unstructured data, such as text, images, and audio, because they are able to automatically extract and learn the most important features of the data. This can be much more effective and efficient than relying on domain experts to manually identify and extract features from the data.
In addition to being good feature extractors, neural networks are also very flexible and can be used for a wide range of tasks, including classification, regression, and clustering. They are also able to adapt and improve their performance over time, making them a powerful tool for building machine learning models.
Let us build a simple neural network to see how quickly it is to accomplish this in Keras
We will build here a Sequential model which is a linear stack of layers, where we can use the large variety of available layers in Keras. It is called a Sequential model because it allows you to build models layer by layer in a sequential fashion, rather than defining a complex graph of interactions.
Practical Session
Now we will build a network that takes two numbers as an input, passes them through a hidden layer of 10 neurons, and finally outputs a single non-constrained number.
Here are the codes you need to run in your notebook to build this neural network
| from tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Densemodel = Sequential() |
This code creates a Sequential model in TensorFlow using the Sequential class from the tensorflow.keras.models module.
| model.add(Dense(10, input_shape=(2,), activation=”relu”)) |
In this case, the model has two layers. The first layer is a Dense layer with 10 units, which means it has 10 neurons. This layer also has an input shape of (2,) which means it expects 2-dimensional input data. The input_shape argument specifies the shape of the input data that the model will receive. The activation function for this layer is “relu”, which stands for “rectified linear unit”. This is a common activation function used in neural networks.
| model.add(Dense(1)) |
The second layer is also a Dense layer, but it has only 1 unit, which means it has only 1 neuron. This layer does not have an activation function specified, so it will use the default activation function, which is the identity function.
| model.summary() |
The summary method provides a summary of the model, including the number of layers, the number of parameters in each layer, and the shape of the output of each layer. This can be helpful for understanding the structure of the model and for debugging.
This is how your output should look like:
 |
The model summary shows there are 30 parameters, 20 from the connections of our inputs to our hidden layer and 10 from the bias weight of each neuron in the hidden layer.
We have learned to create the model, it is time for us to learn how to compile, train, predict and evaluate our model.
Compiling the model in Keras
We compile the model by calling the compile method. The compile method receives an optimizer, which we will use as the algorithm to update our neural network weights, and a loss function, which is the function we want to minimize during training.
Here we will use ADAM as our optimizer and mean squared errors as our loss function. Post compiling our model gets ready to rain.
Optimizer in Keras
It is a function that is used to update the model’s weights based on the gradient of the loss function. There are many different optimizers available in Keras, such as SGD, Adam, and RMSprop. Each optimizer has its own set of hyperparameters that can be tuned to improve the model’s performa
The loss function
It is a measure of how well the model is performing on a particular task. For example, in a regression task, the loss function is the mean squared error, which measures the difference between the predicted values and the true values.
Training a model in Keras
It involves feeding the model a set of input features (X_train) and the corresponding ground truth labels (y_train). The model will then use these data points to update its internal parameters, or weights, so that it can make better predictions on future data.
To train the model, we call the fit method and pass in the training data and labels, as well as the number of epochs to train for. An epoch is a single pass through the entire training dataset. During each epoch, the model will make predictions on each training example and use the loss function to measure how well it did. It will then use the optimizer to update the weights in an effort to improve the model’s performance.
As the model is being trained, it will output progress information such as the loss and any additional metrics that you specified during the compile step. In the example you provided, the loss is the mean squared error, which is a measure of how well the model is predicting the labels. If the loss is decreasing at each epoch, it means that the model is improving and making more accurate predictions on the training data.
Predicting a model output in Keras
To make predictions, we use the predict method of your model. This method takes an array of input data and returns an array of predictions for each sample.
Evaluating a model output in Keras
We use the evaluate method in Keras to evaluate the performance of a model on a given dataset. It does this by performing feed-forward, which consists of computing the model’s output given a set of inputs, and comparing the output to the true values of the labels (y_test). The method then calculates an error metric, such as mean squared error, to measure the difference between the predicted and true values.
Now we will build a simple regression model to predict the orbit of the meteor!
As mentioned earlier our training data consist of measurements taken at time steps from -10 minutes before the impact region to +10 minutes after. Each time step can be viewed as an X coordinate in the graph, which has an associated position Y for the meteor orbit at that time step.
We can view this problem as approximating a quadratic function via the use of neural networks.
Our data is stored in two numpy arrays: one called time_steps , what we call features, and another called y_positions, with the labels. We will now go ahead and build our model! We will predict the y positions for the meteor orbit at future time steps.
Here are the codes you need to run in your notebook to build this model
| model = Sequential()model.add(Dense(50, input_shape=(1,), activation=’relu’)) |
This code creates a Sequential model in Keras, which is a model that consists of a linear stack of layers. The model starts with a single Dense layer that has 50 neutrons and an input shape of 1 neuron. This means that the layer will expect to receive input data with a single feature.
| model.add(Dense(50, activation=’relu’))model.add(Dense(50, activation=’relu’)) |
The model then adds two more Dense layers, each with 50 neurons and a relu activation function. The relu activation function is a common choice for neural networks because it helps to introduce non-linearity into the model, which can improve its ability to learn complex patterns in the data.
| model.add(Dense(1)) |
Finally, the model ends with a Dense layer with a single neuron and no activation function. This is a common choice for regression tasks, as it allows the model to output a continuous value rather than a probability.
With this architecture, the model will have a total of 4 layers, and each layer will be fully connected to the previous and subsequent layers. This means that every neuron in a given layer is connected to every neuron in the previous and next layers.
Now we will compile our model:
| model.compile(optimizer=”adam”, loss=”mse”)print(“Training started…, this can take a while:”) |
In this code, the model is compiled using the compile method. The optimizer is added for updating the model’s weights based on the gradient of the loss function, and the loss function is added to see how well the model is performing.
| model.fit(time_steps, y_positions, epochs=30) |
Post model compilation, it is fit to the data using the fit method. This method takes the input data (time_steps) and the corresponding labels (y_positions) as arguments, as well as the number of epochs to train for (30 here).
| print(“Final loss value:”,model.evaluate(time_steps, y_positions)) |
After training, the model’s performance can be evaluated using the evaluate method. This method takes the same input data and labels as the fit method and returns the average loss over all samples in the dataset. In this case, the returned loss value is the mean squared error, which can be used to gauge the model’s accuracy.
This is how our output will be

Now we will predict the orbit!
We have already trained a model that approximates the orbit of the meteor approaching Earth. Since we trained our model for values between -10 and 10 minutes, our model hasn’t yet seen any other values for different time steps. We will now visualize how your model behaves on unseen data.
The model.predict method is used to make predictions with the model. It takes an array of input data and returns an array of predictions. In this case, the input data is created using the np.arange function from NumPy, which creates an array of evenly spaced values between -10 and 11 (inclusive).
| twenty_min_orbit = model.predict(np.arange(-10, 11)) |
The plot_orbit function is called with the predictions as an argument.
| plot_orbit(twenty_min_orbit) |
This is how output will look like:
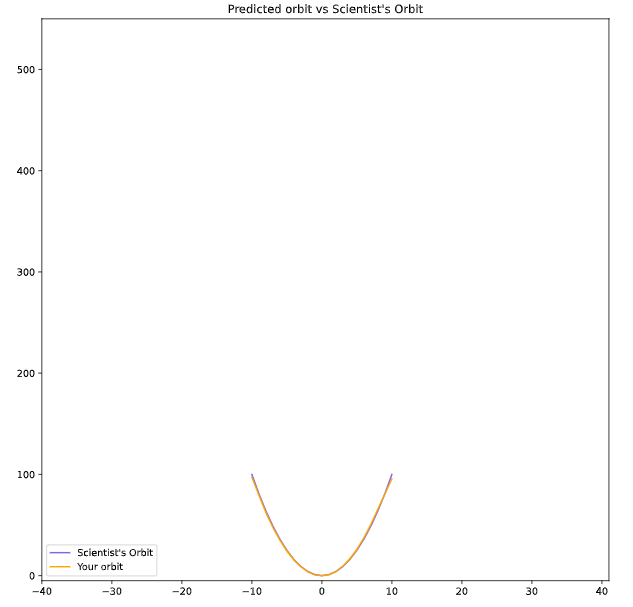
Next, we will predict the 80 minutes orbit
| eighty_min_orbit = model.predict(np.arange(-40, 41)) |
The plot_orbit function is called with the predictions as an argument.
| plot_orbit(eighty_min_orbit) |
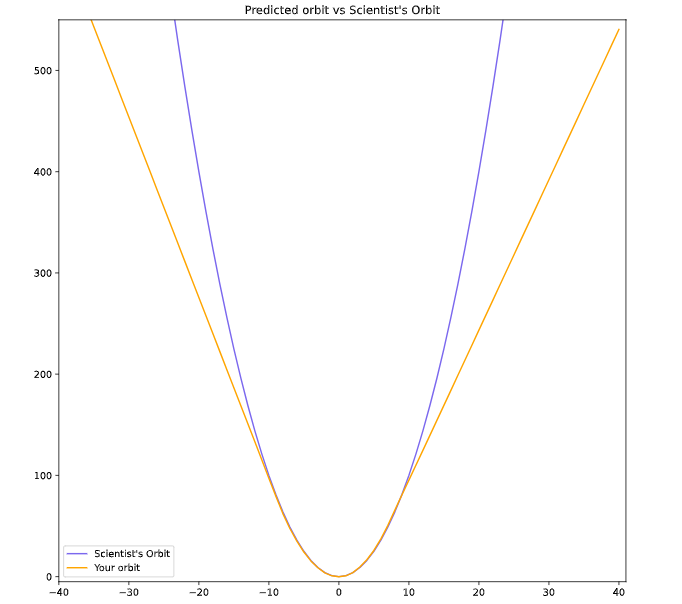
Result and Conclusion
It seems that our model is able to make similar predictions to scientists for the time values between -10 and 10, but starts to diverge when making predictions for new values that were not included in the training data.
This is a common characteristic of machine learning models, including neural networks. They are designed to learn patterns and relationships in the training data and use that knowledge to make predictions on new data. However, if the training data does not accurately represent the relationships in the data that the model is trying to predict, the model may not generalize well to new data and may make inaccurate predictions.
This is why data quality and diversity are so important when training machine learning models. It’s important to have a diverse and representative set of data so that the model can learn the relevant patterns and relationships in the data and make accurate predictions on new data.